

Enhancing Large Language Models: A Guide to Optimizing RAG Pipelines
Years ago, the idea of a machine understanding and generating human-like text with remarkable accuracy seemed like science fiction. Today, this is a reality thanks to Large Language Models (LLMs) like GPT-3 and GPT-4. These models have revolutionized various industries, from customer service to content creation, by providing intelligent, context-aware responses. However, as powerful as they are, LLMs are not without their limitations. They often struggle with providing up-to-date and verifiable information, leading to challenges such as outdated knowledge and lack of sources.
Enter Retrieval-Augmented Generation (RAG) – a groundbreaking framework that combines the generative prowess of LLMs with a robust retrieval mechanism. RAG enhances the accuracy and reliability of LLM responses by grounding them in real-time, relevant data. Off course RAGs also have their own limitations and optimization strategies. Let’s explore those strategies to optimize RAG pipelines, making them more efficient and dependable, and ensuring that our interactions with these advanced models are as accurate and informative as possible.
Understanding the RAG Framework
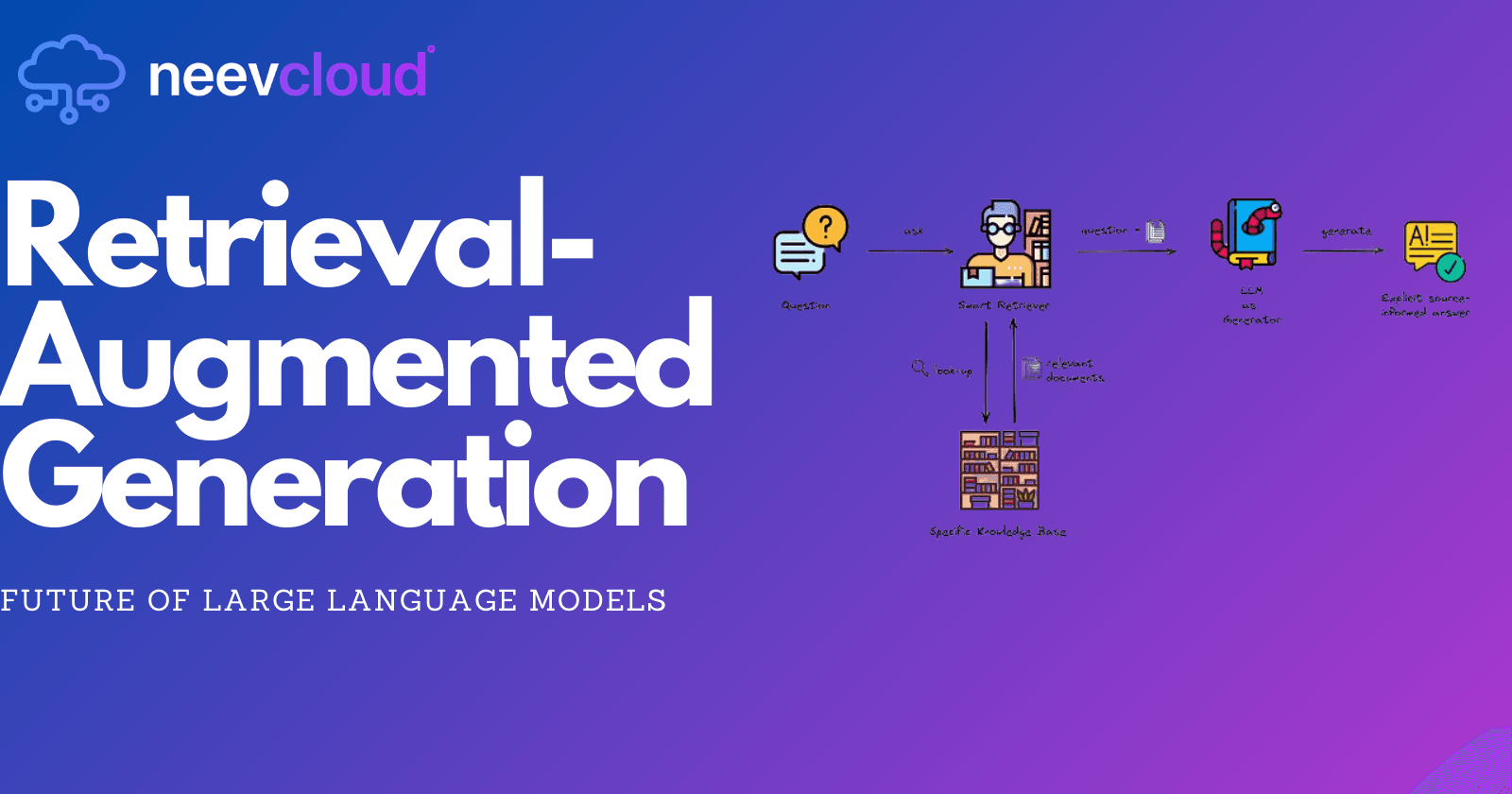
RAG combines the generative capabilities of LLMs with a retrieval mechanism that fetches relevant information from a content store. This approach mitigates issues like outdated knowledge and lack of sources by grounding responses in up-to-date, verifiable data. Here’s how it works in brief:
User Query: The user provides a query or prompt.
Retrieval: The model retrieves relevant information from a content store.
Generation: The model combines the retrieved information with the query to generate a response.
Challenges in RAG Pipelines
Retrieval-Augmented Generation (RAG) systems present a transformative approach to enhancing the utility of large language models (LLMs) by integrating them with retrieval mechanisms. However, these advancements don't come without their hurdles. One key challenge is ensuring the relevance and freshness of information retrieved by RAG systems to support LLMs; outdated data can significantly decrease the response quality, leading to inaccuracies. Another primary issue involves the sourcing of information. When answers are generated based on extensive databases or the internet, validating the credibility and accuracy of the sources quickly becomes a critical concern. Additionally, managing the vast amount of data for retrieval and ensuring the system efficiently selects the most relevant content poses significant logistical and technical difficulties. Therefore, before relying completely on the results produced by the combination of LLM and RAG it's crucial to maintain the quality of retrieved content, address latency introduced during retrieval, and seamlessly integrate retrieval and generation components while preserving high performance levels.
Strategies for Optimizing RAG Pipelines
1. Improving Retriever Performance
Enhancing the performance of the retriever is crucial for the effectiveness of a RAG pipeline. Using advanced retrieval algorithms like dense passage retrieval (DPR) or hybrid methods that combine both keyword-based and meaning-based searches can significantly improve the accuracy of the retrieved information. Basically, these models work by understanding not just the keywords in a query, but also the context and meaning behind them, making the search results more relevant and accurate. Fine-tuning retrievers with domain-specific data also ensures that they are better suited to understand and retrieve relevant documents for specialized queries.
2. Reducing Latency
Latency is a common issue in RAG pipelines, especially with large datasets. To tackle this, efficient indexing techniques like FAISS (Facebook AI Similarity Search) can be used to speed up the retrieval process. FAISS works by organizing data in a way that makes searching faster. Caching frequently accessed data also helps by storing popular information so it doesn’t need to be retrieved from scratch each time. Additionally, using parallel processing allows the system to handle multiple retrieval and generation tasks simultaneously, which significantly reduces overall response time and enhances the user experience.
3. Enhancing Integration
For a RAG pipeline to function smoothly, seamless integration between the retrieval and generation components is essential. Using pipeline orchestration tools can help manage and streamline the processes, ensuring that both components work together efficiently. A modular design approach allows different parts of the RAG pipeline to be updated and optimized independently, which can enhance the overall system performance. Leveraging APIs for communication between the retriever and generator ensures minimal overhead and maximum compatibility, contributing to a more cohesive and efficient pipeline.
4. Ensuring Up-to-Date Information
Maintaining an up-to-date content store is crucial for accurate RAG pipeline responses. Automated update processes are essential for regularly adding new information, ensuring the content stays current. For example, setting up a system that automatically pulls in the latest data can help keep the information fresh. Additionally, version control systems are helpful for managing and tracking changes, making it easier to organize and update the repository. Now that you have the updated content, make sure to fill the content store with verified and reputable sources, which enhances the credibility of the responses and reduces the risk of sharing inaccurate or outdated information. By combining these strategies, you can ensure that your RAG pipeline remains reliable and trustworthy.
Optimizing RAG pipelines bridges the gap between current limitations and the potential of LLMs, offering a robust architecture to improve content generation. By leveraging retrieval augmented generation, LLMs can access an external collection of documents—the knowledge source—and effectively answer prompts with the most up-to-date and relevant information. The augmentation results in systems that are less likely to "hallucinate" or present outdated facts, because they fetch the latest data instead of relying heavily on previously trained datasets. Furthermore, these systems provide references to the source material, increasing the credibility and reliability of the responses they generate. RAG pipelines promise significant advancements in various applications where precision, up-to-date content, and reliability are critical, such as interactive chatbots, sophisticated research tools, and customized knowledge bases. By focusing on enhancing both the retrieval and generation aspects, organizations can harness the full potential of LLMs in practical, impactful ways.




